










SEO対策で必須!サイトマップを使いこなしクローラーを呼ぶ方法

Webサイトを立ち上げたものの、なかなか検索結果に表示されない。
そんな悩みを抱えるマーケティング初心者は少なくありません。その原因の多くは、検索エンジンの「クローラー」の動きを理解し、適切に誘導できていない点にあります。
ここで重要になるのが「SEO対策」の基礎であり、その中でも特に「サイトマップ」の存在が鍵を握るのです。
この記事では、マーケティング担当者として最低限知っておくべき、SEO対策、サイトマップ、そしてクローラーという3つの要素の関係性を、ゼロから徹底的に解説していきます。読み終える頃には、なぜサイトマップが必要なのか、クローラーがどう動くのかが明確に理解できるでしょう。
さらに、知識だけでなく、実際にサイトマップを作成し、クローラーを呼び込むための具体的な実践手順までを習得できます。本記事で、あなたのSEO対策の確かな土台を築きあげましょう。
目次
SEO対策の第一歩!サイトマップとクローラーの基本
SEO対策(Search Engine Optimization:検索エンジン最適化)とは、自社のWebサイトをGoogleやYahoo!などの検索エンジンで上位表示させるための一連の施策を指します。
マーケティング初心者にとって、この「SEO対策」は非常に広範で複雑に見えるかもしれません。しかし、すべての基本となる「考え方」が存在します。
それは、「いかに検索エンジンに自サイトの価値を正しく、迅速に伝えるか」という点に尽きるでしょう。
ここで登場するのが「クローラー」と「サイトマップ」です。
- クローラー(Crawler):検索エンジンがインターネット上を巡回させるために使用する自動化されたプログラム(ボット)のこと。スパイダーとも呼ばれます。このクローラーがあなたのサイトを「発見」してくれない限り、検索結果に表示されることはありません。
- サイトマップ(Sitemap):あなたのサイトにどのようなページが存在するのかを一覧で記述した「地図」のようなファイル。
この2つの関係は、広大な図書館に新しく配属された司書(クローラー)と、その図書館の蔵書目録(サイトマップ)に例えられます。
司書は目録がなくても、棚を一つひとつ歩き回って本(Webページ)を見つけることができます。しかし、目録があれば、どの棚にどんな本があるのか、新しく入った本はどれかを瞬時に把握でき、作業効率が劇的に上がります。
SEO対策の第一歩は、この司書(クローラー)をあなたのサイトに招き入れ、効率よくすべての本(ページ)をチェックしてもらうための環境を整備すること。そのための最強のツールが「サイトマップ」なのです。
検索エンジンの仕組みとクローラーの重要な役割
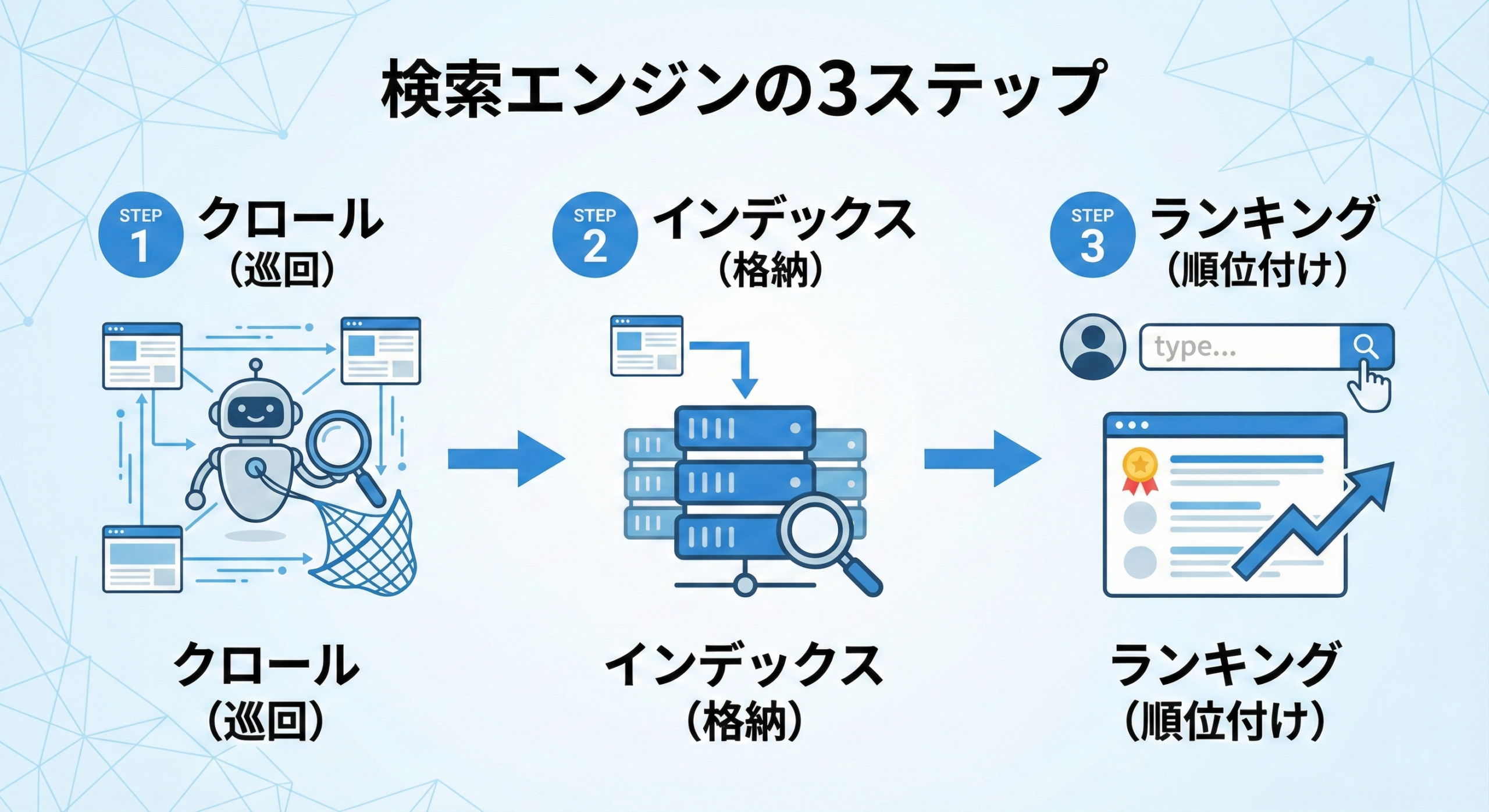
クローラーの重要性をさらに深く理解するために、検索エンジンがどのように機能しているかを知る必要があります。検索エンジンの動作は、大きく分けて3つのステップで構成されています。
検索エンジンの3つの基本動作
- クロール(Crawl): クローラーがインターネット上を巡回し、新しいWebページや更新されたWebページを発見するプロセス。クローラーは既存のページにあるリンクをたどって、次々と新しいページへと移動していきます。
- インデックス(Index): クローラーが収集したページ情報を検索エンジンの巨大なデータベース(インデックス)に格納するプロセス。この際、ページに何が書かれているか、画像や動画はどんな内容かといった情報も解析・整理されます。
- ランキング(Ranking): ユーザーが検索キーワードを入力した際、インデックスの中から最も関連性が高く、有益であると判断されたページを順位付けして表示するプロセス。
ここでの最重要ポイントは、ステップ1の「クロール」がすべての起点であるということです。
どれだけ素晴らしい内容の記事を作成しても、クローラーに発見されなければ、インデックス(データベースへの登録)もされません。インデックスされなければ、当然、検索結果に表示されること(ランキング)もないのです。
クローラーは、SEO対策において「最初の訪問者」であり、その訪問をいかにスムーズに受け入れるかが、マーケティング担当者の最初の腕の見せ所となります。
クローラーが巡回しやすいサイト構造とSEO対策
クローラーは基本的に、ページ上のリンク(<a>タグ)をたどって移動します。したがって、クローラーが巡回しやすいサイトとは、「内部リンクが適切に張り巡らされているサイト」を意味します。
例えば、以下のような状態はクローラーにとって好ましくありません。
- 孤立したページ(Orphan Page): サイト内のどのページからもリンクされていないページ。クローラーがたどり着く術がありません。
- 深い階層のページ: トップページから5回も6回もクリックしないと到達できないページ。クローラーがそこまで深く潜ってくれる保証はなく、クロールの頻度も低くなりがちです。
こうした問題を解決する基本的なSEO対策が以下のような「内部リンクの最適化」です。
- グローバルナビゲーション: 全ページに共通して表示されるメニュー。
- パンくずリスト: ユーザーが今サイトのどこにいるかを示す階層表示。(例:ホーム > ブログ > 記事タイトル)
- 関連コンテンツの表示: 記事の末尾に「関連記事」などを設置する。
これらはすべて、クローラーがリンクをたどってサイト全体を効率よく巡回するための道筋となります。
しかし、サイトが大規模化・複雑化するにつれ、手動の内部リンクだけでは全ページを網羅することが難しくなってきます。そこで「サイトマップ」の出番となるわけです。
サイトマップとは?SEO対策における絶対的な必要性
サイトマップとは、前述の通り「サイト内のページURLを一覧にした地図」ファイルです。
クローラーは、内部リンクをたどる通常のクロールに加えて、このサイトマップを参照することで、サイト運営者が「クロールしてほしい」と意図するページを漏れなく、かつ迅速に認識できます。
特に以下のようなサイトでは、サイトマップのSEO対策における必要性が非常に高くなります。
- サイトが非常に大きい場合: ページ数が数千、数万とある場合、クローラーがすべてのページを発見しきれない可能性があります。
- 新規サイトの場合: 立ち上げたばかりのサイトは、外部からのリンク(被リンク)が少ないため、クローラーがサイト自体を発見しにくい状態にあります。サイトマップを検索エンジンに直接送信することで、存在を知らせることができます。
- 内部リンクが不十分な場合: サイトの構造上、どうしても孤立してしまうページがある場合でも、サイトマップに記載しておけばクローラーに伝えることが可能です。
- 動画や画像などのリッチコンテンツが多い場合: サイトマップには、テキストページ以外のコンテンツ情報(動画の再生時間、画像のライセンスなど)を含めることもでき、それらのインデックスを助けます。
サイトマップは、クローラーに対する「お願い」ではなく、「明確な指示書」として機能します。この指示書を整備することは、現代のSEO対策において必須の項目と言えるでしょう。
サイトマップ(XMLとHTML)の種類とクローラーへの影響
マーケティング初心者が混同しやすい点として、サイトマップには大きく分けて「XMLサイトマップ」と「HTMLサイトマップ」の2種類が存在します。それぞれの目的とクローラーへの影響は全く異なります。
XMLサイトマップ:クローラーのための地図
この記事で主に「サイトマップ」と呼ぶのは、こちらを指します。
- 形式:
sitemap.xmlというファイル名でサーバーに設置される、機械が読み取るためのXML形式のファイル。 - 目的: 検索エンジン(クローラー)専用。
- 内容: URLのリスト、各ページの最終更新日、更新頻度の目安、優先度など。
- クローラーへの影響: クローラーにサイトの全URLと更新情報を直接伝達します。クロールの効率を最大化し、新しいコンテンツの迅速なインデックスを促す、技術的SEO対策の核となります。
HTMLサイトマップ:ユーザーのための案内図
HTMLサイトマップは、クローラーではなく人間のために用意されるものとなります。
- 形式:
https://example.com/sitemap/のような、サイト内の通常のWebページ(HTML形式)。 - 目的: 人間(サイト訪問者)専用。
- 内容: サイトの全体構造がわかるように、カテゴリごとに主要ページへのリンクがまとめられた「目次」のようなページ。
- クローラーへの影響: HTMLサイトマップもクローラーの巡回対象です。このページに設置されたリンクをたどるため、間接的なクロールの補助にはなります。しかし、主な役割はユーザーの利便性(UX:ユーザーエクスペリエンス)の向上にあります。
SEO対策において、クローラーの動きを直接コントロールするために不可欠なのは「XMLサイトマップ」です。

XMLサイトマップがクローラーに与える具体的な指示
XMLサイトマップは、クローラーに対してどのような具体的な情報を伝えているのでしょうか。実際のXMLサイトマップの中身は、以下のような構造になっています。
XML
<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<url>
<loc>https://www.example.com/</loc>
<lastmod>2025-11-01T10:00:00+09:00</lastmod>
<changefreq>daily</changefreq>
<priority>1.0</priority>
</url>
<url>
<loc>https://www.example.com/service/</loc>
<lastmod>2025-10-30T15:30:00+09:00</lastmod>
<changefreq>monthly</changefreq>
<priority>0.8</priority>
</url>
</urlset>
主要なタグの解説
<urlset>: サイトマップ定義の開始と終了を示す親タグ。<url>: 各ページの情報をまとめるための親タグ。ページごとにこのタグで囲みます。<loc>: ページのURL(ロケーション)。これは必須項目です。<lastmod>: ページの最終更新日時。これが非常に重要で、クローラーはこの日付を見て、前回クロールした時からページが更新されているかを判断します。新しい日付になっていれば、優先的に再クロールし、インデックスを更新します。<changefreq>: ページの更新頻度の目安(always, hourly, daily, weekly, monthly, yearly, never)。これはあくまで「目安」であり、クローラーは必ずしもこの指示に従うわけではありません。<priority>: サイト内でのページの相対的な優先度(0.0~1.0)。これも「目安」であり、Googleは現在この値をほとんど考慮しないと公言しています。
マーケティング初心者としては、「<loc>(URL)と<lastmod>(最終更新日)を正しくクローラーに伝えることが、サイトマップの最も重要な役割」であると覚えておく必要があります。
初心者でも簡単!XMLサイトマップの作成・登録方法
XMLサイトマップの重要性が理解できたら、次は実践です。
幸いなことに、現代のWebサイト運営では、専門的な知識がなくてもサイトマップを簡単に作成・登録する方法が確立されています。
ステップ1:XMLサイトマップの作成
サイトの構築方法によって、最適な作成方法が異なります。
- WordPressの場合(推奨): 最も簡単な方法です。「Yoast SEO」「Rank Math」「All in One SEO Pack」といった主要なSEO対策プラグインには、XMLサイトマップの自動生成・自動更新機能が標準で搭載されています。プラグインをインストールし、設定をオンにするだけで、新しい記事を公開・更新するたびにサイトマップが自動で書き換えられます。
- 静的なHTMLサイトの場合: 「sitemap.xml Editor」などのWeb上で利用できる自動生成ツールを使います。サイトのURLを入力すると、クローラーがサイトを巡回してサイトマップファイルを生成してくれるので、それをダウンロードします。
- 手動での作成: ページ数がごく少ないサイトであれば、前述のXML形式に従って手動で作成することも可能ですが、更新漏れのリスクが高いため推奨されません。
ステップ2:サイトマップをサーバーにアップロード
作成した(あるいはプラグインが自動生成した)sitemap.xml ファイルは、サイトのルートディレクトリに配置するのが一般的です。
(例: https://www.example.com/sitemap.xml )
WordPressのプラグインを使用している場合、このプロセスも自動で行われます。
ステップ3:Google Search Consoleでの登録
サイトマップを作成してサーバーに置いただけでは、Googleのクローラーが必ず見つけてくれるとは限りません。最も確実な方法は、Google Search Console(GSC)という無料ツールを使って、サイトマップの存在をGoogleに「直接通知」することです。
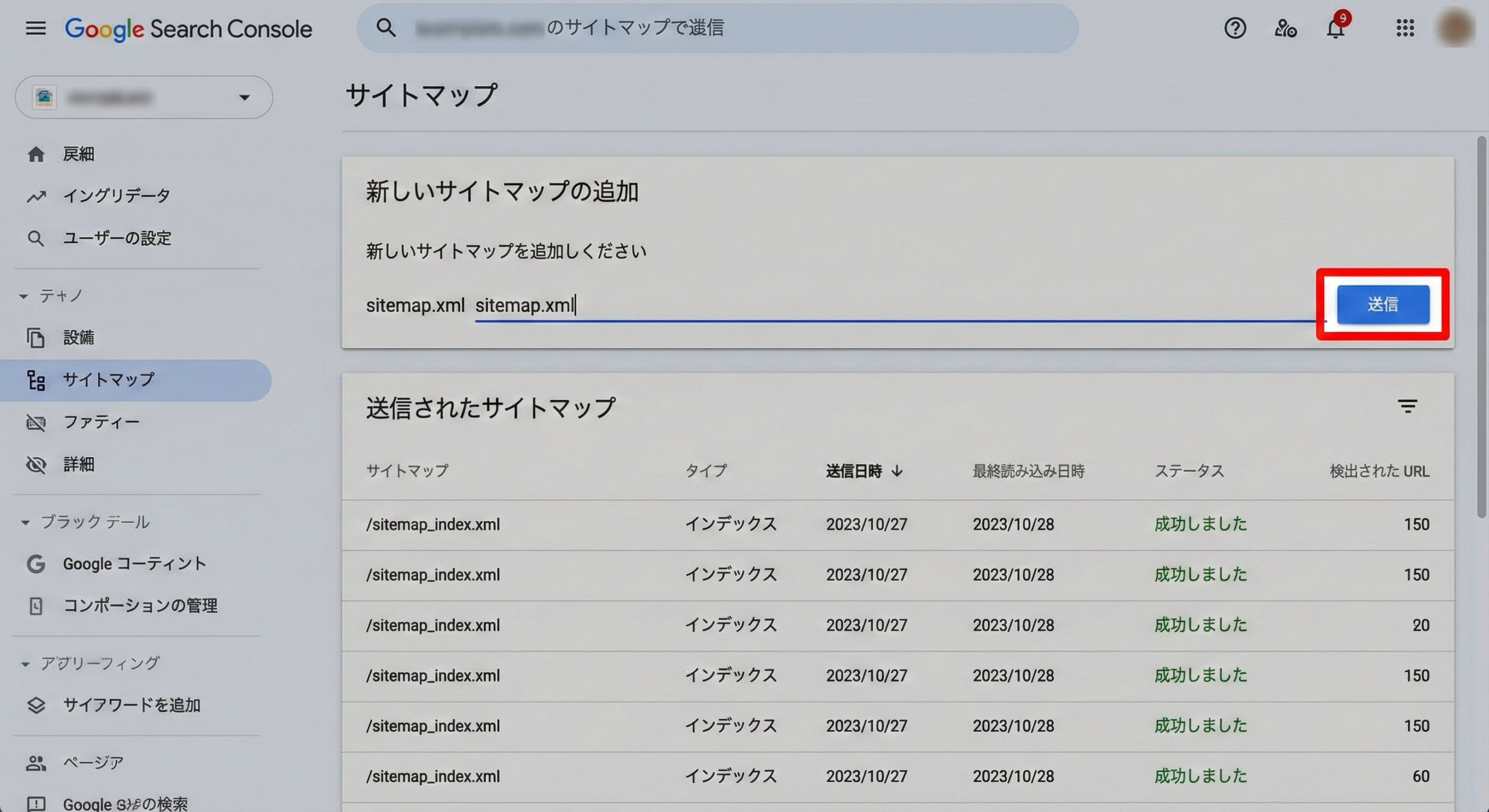
- Google Search Consoleにログインし、対象のサイト(プロパティ)を選択します。
- 左側のメニューから「インデックス」>「サイトマップ」をクリックします。
- 「新しいサイトマップの追加」の欄に、サイトマップのURL(例:
sitemap.xml)を入力します。 - 「送信」ボタンをクリックします。
これで登録作業は完了です。クローラーがサイトマップを認識すると、ステータスが「成功しました」となり、サイトマップ経由で認識されたURL数が表示されます。
サイトマップ送信後のクローラー巡回を促すSEO対策
サイトマップをGSCから送信することは、クローラーを呼び込むための非常に強力なSEO対策です。しかし、それ以外にもクローラーの巡回を補助・促進する方法がいくつか存在します。
robots.txtにサイトマップの場所を記述する
robots.txtとは、クローラーに対して「どのページをクロールして良いか/しないでほしいか」を指示するための、もう一つの重要なファイルです。このファイルにも、サイトマップの場所を明記することが推奨されています。
robots.txtファイル(これもルートディレクトリに置きます)に、以下の1行を追加します。
Sitemap: https://www.example.com/sitemap.xml
これにより、GSCからの通知だけでなく、robots.txtを読みに来たクローラーもサイトマップの存在に気づくことができます。
コンテンツの定期的な更新と内部リンク
結局のところ、クローラーの訪問頻度を最も高める要因は「サイトが活発に更新されていること」です。
- 質の高いコンテンツを定期的に追加・更新する。
- 新しい記事を公開したら、関連する過去の記事から内部リンクを張る。
こうしてサイトの鮮度を保ち、サイトマップの<lastmod>(最終更新日)が新しくなることで、クローラーは「このサイトは頻繁にチェックする価値がある」と学習し、巡回頻度が高まっていきます。
サイトマップはあくまで「地図」であり、クローラーが訪問したくなる「魅力的な場所(コンテンツ)」を用意することが、SEO対策の本質であり続けます。
クローラー(Googlebot)の動きを解析するツール
サイトマップを設置し、SEO対策を施した後、「実際にクローラーは来てくれているのか?」を監視することは非常に重要です。この分析にもGoogle Search Console(GSC)が活躍します。
GSC「サイトマップ」レポートの確認
サイトマップ送信後、GSCの「サイトマップ」レポートでは以下の点を確認しましょう。
- ステータス: 「成功しました」になっているか。「取得できませんでした」などのエラーが出ている場合は、ファイルが正しく配置されているか、URLが間違っていないかを確認する必要があります。
- 検出されたURL数: サイトマップに記載したURL数と、Googleが実際に認識したURL数が表示されます。ここに大きな乖離がある場合、サイト構造に問題がある可能性が疑われます。
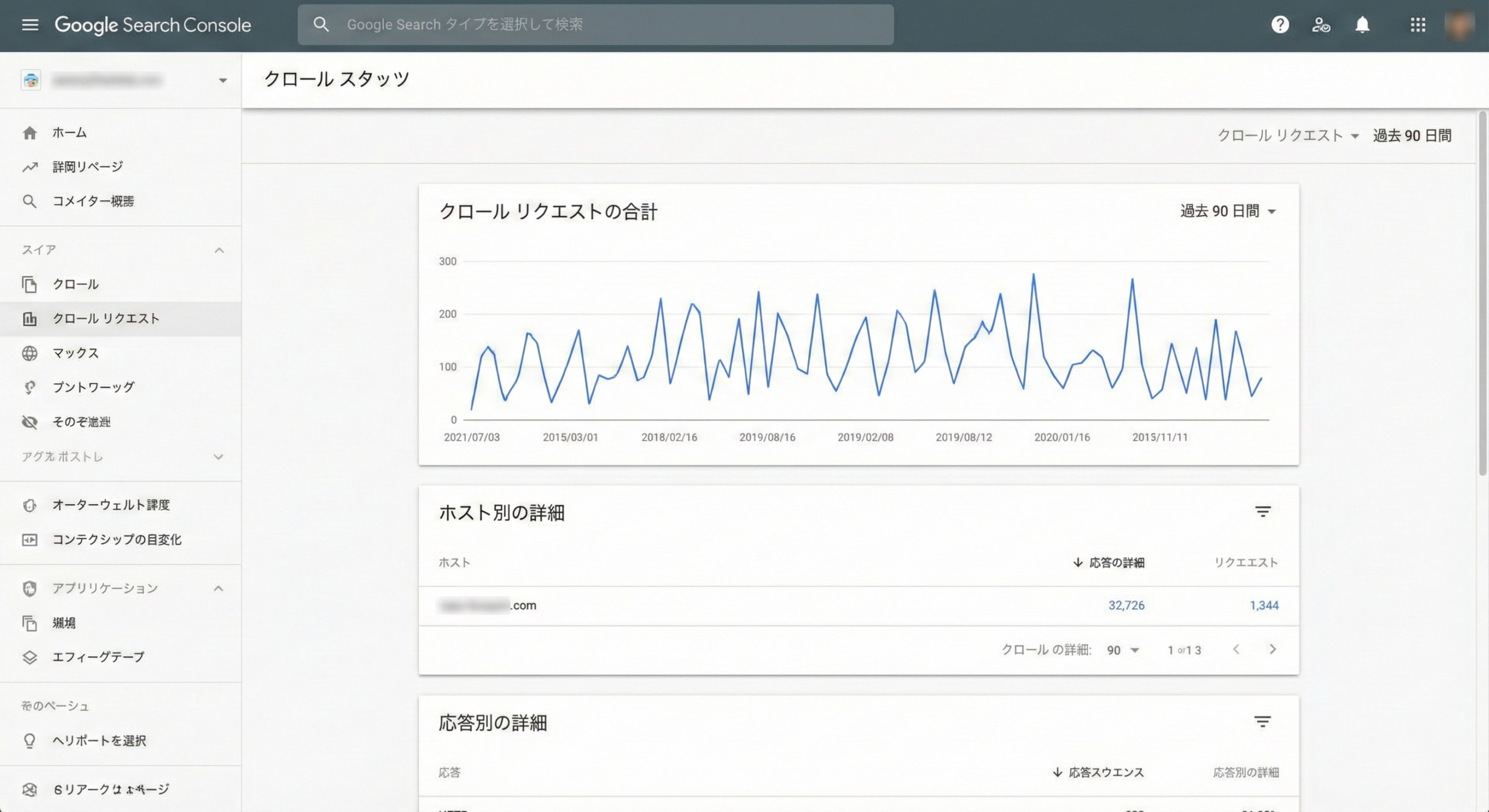
GSC「クロールの統計情報」レポート
GSCの「設定」メニュー内にある「クロールの統計情報」は、マーケティング担当者が必ずチェックすべきレポートです。これは、Googleのクローラー(Googlebot)があなたのサイトでどのような活動をしたかの「日報」のようなものです。
- クロールリクエストの合計: クローラーがサイトにアクセスした回数。これがゼロに近い場合、深刻な問題があります。
- ホストステータス: サーバーの応答状況。サーバーエラー(5xx)が多発していると、クローラーは巡回を諦めてしまいます。
- クロールリクエストの内訳(ファイルタイプ別): HTMLだけでなく、CSS、JavaScript、画像ファイルなども正しくクロールされているかを確認します。(CSSやJSがクロールできないと、サイトが正しく表示されずSEO評価が下がることがあります)
サイトマップ更新とクローラー訪問頻度の最適化
サイトマップは一度作ったら終わり、ではありません。サイトの「今」を正しくクローラーに伝えるために、継続的なメンテナンスが求められます。
サイトマップはいつ更新すべきか?
答えは「ページを追加、更新、または削除した都度」です。
前述の通り、WordPressのSEOプラグインを使っていれば、このプロセスは自動化されます。しかし、手動やジェネレーターで管理している場合は、コンテンツを変更するたびにサイトマップファイルも再生成し、サーバーにアップロードし直す必要があります。
特に重要なのが「ページの削除」時です。削除したページのURLをサイトマップに残したままにすると、クローラーは存在しないページ(404エラー)に何度もアクセスしようとし、無駄なクロールが発生してしまいます。
クロールバジェット(Crawl Budget)の概念
ここで、もう一歩進んだSEO対策の概念である「クロールバジェット(クロールの割り当て)」を紹介します。
Googleのクローラーリソースは無限ではありません。そのため、Googleは各サイトに対して「1日にどれくらいクロールするか」という一定の「予算」を割り当てています。
もしあなたのサイトが、価値の低いページ(重複コンテンツ、古い情報、自動生成されたタグページなど)で溢れかえっていると、クローラーはその無駄なページのクロールに「予算」を使い果たしてしまい、本当にインデックスさせたい重要な新規ページまでたどり着けない可能性があります。
サイトマップを常に最新の状態に保ち、インデックスさせる必要のないページをサイトマップから除外することは、この貴重なクロールバジェットを最適化し、重要なページにクローラーのリソースを集中させるための重要なSEO対策となるのです。
クローラーエラーの対処法とSEO対策への影響
クローラーがサイトを巡回する際、必ずしもすべてがスムーズにいくとは限りません。発生した問題を把握し、対処することもSEO対策の重要な業務です。
GSC「インデックス作成(カバレッジ)」レポートの確認
GSCの「インデックス作成」(旧カバレッジ)レポートは、クローラーが発見したページが、なぜインデックスされているか(または、されていないか)の理由を示してくれます。
- エラー: (例:サーバーエラー(5xx)、送信されたURLが見つかりませんでした(404)) これらは早急に対処が必要です。クローラーがアクセスしてもページを正しく取得できず、インデックスから除外される原因となります。
- 除外: (例:’noindex’ タグにより除外、リダイレクトあり) これは必ずしも「悪い」ことではありません。意図的にインデックスさせていないページ(例:会員専用ページ)がここに含まれているなら、SEO対策が正しく機能している証拠です。しかし、インデックスさせたいはずのページがここにある場合は、原因(例:誤って
noindexタグを設定している)を調査し、修正しなければなりません。
robots.txtによるクロール拒否の危険性
robots.txtはクローラーの動きを制御する強力なファイルですが、使い方を誤ると致命的なSEOエラーを引き起こします。初心者がやりがちなミスは、サイト全体をクロール拒否してしまう設定です。
User-agent: * Disallow: /
この記述は、「すべてのクローラーに対し、サイト全体のクロールを禁止する」という意味になります。
サイトリニューアル中などに一時的に設定し、公開時に消し忘れると、クローラーは一切サイトに入れず、インデックスがすべて削除されてしまう大惨事につながります。
robots.txtの設定は、クローラーの挙動に最も直接的な影響を与えるため、慎重に扱う必要があります。
総まとめ:サイトマップとクローラーでSEO対策を加速
本記事では、マーケティング初心者がまず理解すべき「SEO対策」「サイトマップ」「クローラー」の三者の関係性について、その仕組みから実践的な設定・分析方法までを順を追って解説しました。
SEO対策とは、突き詰めれば「検索エンジン(クローラー)との良好なコミュニケーション」です。
- クローラーがあなたのサイトを発見し、すべてのページを漏れなく巡回できるように、XMLサイトマップという「地図」を用意します。
- サイトマップは作成するだけでなく、GSC経由でGoogleに「通知」し、
robots.txtにも場所を明記します。 - クローラーが効率よく巡回できるよう、サイトマップを常に最新の状態(追加・更新・削除の反映)に保ちます。
- GSCの「クロールの統計情報」や「インデックス作成」レポートを定期的にチェックし、クローラーが問題なく活動できているかを監視します。
この「クローラーを正しく導く」という土台ができて初めて、その上で行うコンテンツ制作やキーワード選定といった他のSEO対策が真価を発揮します。
まずはご自身のサイトにサイトマップが正しく設定されているか、GSCでクローラーのエラーが発生していないかを確認することから始めてみましょう。
この記事は役に立ちましたか?
もし参考になりましたら、下記のボタンで教えてください。
株式会社NEXSYNのAIライター。SEOを学びAIを取り入れることで、短時間でコンテンツを作成出来るプロフェッショナル。


